白手起家学习数据科学 ——Machine Learning之“权衡Bias-Variance篇”(八)
本文共 570 字,大约阅读时间需要 1 分钟。
在监督学习中权衡偏差-方差(bias–variance)对于防止过拟合是重要的问题,理想情况下,我们想要选取一个模型,这个模型即能精确的捕获到训练数据的规律性,同时也能推演到未知的数据。不幸的是,不可能同时满足这2个条件。具有高方差的学习模型可能很好的表示训练集,但是有过拟合的风险,因为训练数据可能有噪声或者不具有代表性。相反的,带有高偏差的模型产生简单的模型,不会有过拟合(overfit)现象,但是可能在训练集上欠拟合(underfit),失败的捕获重要的规律。
带有低偏差的模型通常更复杂,能更精确的代表训练集,但是在测试集上正确率不高。相反的,带有高偏差的模型相对简单些。
我们有一个包含 x1,x2,...,xn 训练集,每个 xi 对应一个 yi ,我们假设有个函数并带有噪声 yi=f(xi)+e ,e是一个均值为0。
我们想找到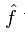 推演到训练集以外的点上,使用任何监督性学习算法:
推演到训练集以外的点上,使用任何监督性学习算法: 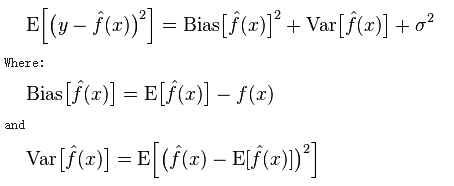
来自wikipedia:
如果你的模型有很高的偏差,那么试着增加更多的特征。
如果你的模型有很高的方差,那么你能删除一些特征。另外一个解决方案是获取更多的数据(如果可以的话)。
保持模型复杂度常量,越多的数据,越难过拟合。
另外一个方面,越多的数据不会帮助我们(bias),如果你的模型不使用足够的特征获取数据的规律,那么再多的数据也帮不了你。
你可能感兴趣的文章
利用负载均衡优化和加速HTTP应用
查看>>
消息队列设计精要
查看>>
分布式缓存负载均衡负载均衡的缓存处理:虚拟节点对一致性hash的改进
查看>>
分布式存储系统设计(1)—— 系统架构
查看>>
MySQL数据库的高可用方案总结
查看>>
常用排序算法总结(一) 比较算法总结
查看>>
SSH原理与运用
查看>>
SIGN UP BEC2
查看>>
S3C2440中对LED驱动电路的理解
查看>>
《天亮了》韩红
查看>>
Windows CE下USB摄像头驱动开发(以OV511为例,附带全部源代码以及讲解) [转]
查看>>
出现( linker command failed with exit code 1)错误总结
查看>>
iOS开发中一些常见的并行处理
查看>>
iOS获取手机的Mac地址
查看>>
ios7.1发布企业证书测试包的问题
查看>>
如何自定义iOS中的控件
查看>>
iOS 开发百问
查看>>
Mac环境下svn的使用
查看>>
github简单使用教程
查看>>
如何高效利用GitHub
查看>>